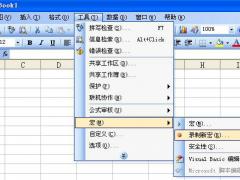
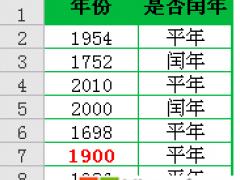
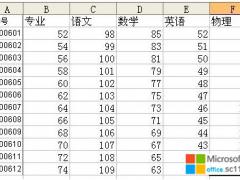
excel唯一值个数7种公式,带大括号的为数组公式,需要按CTRL+SHIFT+ENTER三键结束输入
1 {=SUM(1/COUNTIF(B1:B44,B1:B44))}
2 {=SUM(N(MATCH(B1:B44,B1:B44,)=ROW(1:44)))}
3 {=SUMPRODUCT((B1:B44<>"")/COUNTIF(B1:B44,B1:B44&""))}
4 =SUMPRODUCT(1/COUNTIF(B1:B44,B1:B44))
5 {=SUM(N(FREQUENCY(B2:B45,B2:B45)>0))}
6 {=SUM(--(MATCH(B1:B44,B1:B44,)=ROW(1:44)))}
7{ =SUM(--(FREQUENCY(B1:B44,B1:B44)>0))}
Excel 中用公式列出唯一值——模拟高级筛选功能
在 Excel 中处理数据时,我们经常会遇到包含重复数值的列。比如,员工表或客户表的城市一列,又比如商品销售清单的商品名称一栏。数据处理工作的一个内容可能就是列出这些数据的唯一值,看看哪些城市有客户,供应商或员工,看看哪些商品被卖了出去。这个任务用 Excel 的高级筛选功能是非常容易做到的。不过,也许是出于对算法的追求,有一个用公式的解法来列出唯一值。我不是这个公式的原创者,但还是很愿意解释一下这个公式,看一下例子吧。
| A | B | C | D | |
| 1 | 城市 | 城市 | 位置 | |
| 2 | 上海 | 上海 | 2 | |
| 3 | 上海 | 北京 | 4 | |
| 4 | 北京 | 广州 | 5 | |
| 5 | 广州 | 南京 | 7 | |
| 6 | 广州 | 0 | 11 | |
| 7 | 南京 | #N/A | #N/A | |
| 8 | 北京 | |||
| 9 | 上海 | |||
| 10 | 广州 |
A 栏是包含了重复值的一列城市名,我们要在 C 栏用公式列出唯一的城市名。示例数据中我们用到了列名“城市”,这是个好的习惯,因为用高级筛选功能也是要求原始数据有列名的。
在 C2 输入 =INDEX(A:A,MATCH(0,COUNTIF(C$1:C1,$A$1:$A$11),)),按 CTRL+SHIFT+ENTER 作为数组公式输入。下面来解释一下这个公式的构造:
要在 C 栏列出唯一值,肯定要在原始数据,即 A 栏中进行查找,这是最外面的 INDEX 公式的用处。现在的问题变成,如何构造一个公式能返回每个值第一次出现时的位置。接下来考察一下 Match 这个公式,在 D2 输入 =MATCH(0,COUNTIF(C$1:C1,$A$1:$A$11),),也是按 CTRL+SHIFT+ENTER 作为数组公式输入,从结果可以看出,D 栏列出了每个唯一值在 A 栏第一次出现时的序号或位置。
这个问题可以这样考虑,如果我们能在 C 栏通过公式列出唯一值,那么假定我们已经列出了一部分唯一值。接下来的那个唯一值,也即 A 栏中将要取出的那个值,在 C 栏已有的唯一值列表中是找不到的。也就是说,将要取出的那个值,在 C 栏已有的唯一值列表中出现次数是0。它上面的那些值都已经在 C 栏已有的唯一值列表中出现过了,否则也不会轮到它。这就是 Match 函数要从一个序列中查找 0 值的意义所在。那么,怎么构建一个序列,对应 A 栏中的数据是否在 C 栏中出现过呢?这个序列应该是类似 {1,0,0,1,1,0,……}这个样子,因为 C 栏是唯一值,对于 A 栏中的每个数据在 C 栏中只可能出现一次,返回一个 1,不出现就返回 0。当这个数据在 A 栏中重复出现时,又会返回一个 1,我们期望的序列是和 A 栏的数据一一对应的,对应关系是——这个值是否在 C 栏已有列表中出现过。
用 CountIf 函数来构造这个序列,我只能说这是基于对数组函数和 CountIf 函数本身的及其熟稔才能做到的。CountIf 函数返回的序列的大小(元素个数)和它的第二个参数的大小是一致的。就这个例子而言,COUNTIF(C$1:C1,$A$1:$A$11),表示对 $A$1:$A$11 中的每个数据在 C$1:C1 中进行查找,返回一个是否存在的 0,1值序列。
这个问题的另一个技巧就是 C$1:C1 的半固定表示法。当公式向下复制的时候,C1 会增长为 C2,C3 等等,永远只在已有的唯一值列表中查找。对于 Excel,这是个递归的计算。我们的逻辑,也是用归纳法推出来的。